Juicedata präsentiert JuiceFS als POSIX-kompatibles, auf Objektspeicher basierendes verteiltes Dateisystem, das fragmentierte Speicherarchitekturen in KI-Training, Big Data und Cloud-nativen Umgebungen ablösen soll, wie auf der IT Press Tour gezeigt.
Als Nvidia CEO Jensen Huang Anfang dieses Jahres bei einer Keynote in Taiwan Partnerlogos präsentierte, fertigte ein Produktmanager bei Juicedata einen Screenshot an und bearbeitete die Folie gedanklich. Das eigene Unternehmen fehlte darauf. „Eines Tages werden wir dort sein“, erklärte der Developer Advocate gegenüber Journalisten beim IT Press Tour #68 im Juni 2026 in Boston. Diese Offenheit beschreibt etwas Wesentliches über Juicedata: ein 35-köpfiges, in China ansässiges Unternehmen, das bereits profitabel arbeitet und direkt gegen etablierte Hochleistungs-Dateisystemanbieter konkurriert, im westlichen Unternehmensmarkt jedoch weitgehend unbekannt geblieben ist.
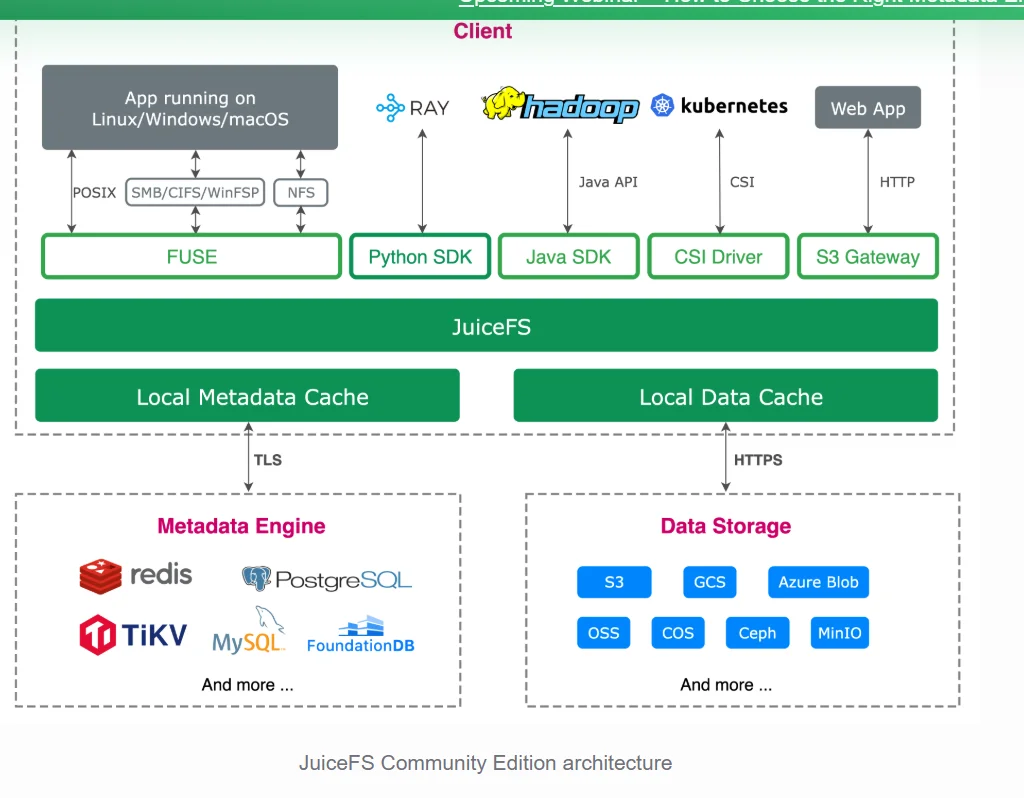
JuiceFS ist ein verteiltes Dateisystem, das auf Objektspeicherdiensten aufgebaut ist. Die Architektur trennt Daten von Metadaten: Tatsächliche Dateiinhalte werden in handelsüblichem Objektspeicher abgelegt — Amazon S3, Google Cloud Storage, MinIO, Ceph oder einem beliebigen S3-kompatiblen Backend — während Metadaten von einer austauschbaren Engine wie Redis, PostgreSQL, TiKV oder dem unternehmenseigenen verteilten Dienst verwaltet werden. Die Client-Schicht spricht POSIX-, HDFS- und S3-Protokolle gleichzeitig, sodass bestehende Hadoop-Pipelines, Python-Machine-Learning-Frameworks und persistente Kubernetes-Volumes dasselbe Dateisystem einhängen können, ohne Codeänderungen vorzunehmen.
Die Entscheidung für Objektspeicher als Grundlage ist bewusst getroffen. Objektspeicher ist praktisch unbegrenzt skalierbar, bietet elf Neunen Datenhaltbarkeit, unterstützt native Multi-Region-Replikation und kostet bei Amazon S3 rund zwei Cent pro Gigabyte im Monat — erheblich weniger als Block- oder speziell entwickelter Dateispeicher. Die Herausforderung war stets, dass Objektspeicher einen flachen Schlüssel-Wert-Namensraum und unveränderliche Objekte anbietet, nicht die hierarchischen Verzeichnisse und Zufallsschreibsemantik, die die meisten Anwendungen erwarten. JuiceFS löst dies, indem Dateien in Blöcke fester Größe aufgeteilt werden, nur die Zuordnung von Chunks zu Objekten in der Metadaten-Engine gespeichert wird und der Anwendung eine standardmäßige POSIX-Schnittstelle präsentiert wird.
Da Umbenennungen und Verschiebungen reine Metadatenoperationen sind — keine Bytes werden zwischen Objekten kopiert — führt JuiceFS sie mit einem einzigen Schreibvorgang in der Metadaten-Engine aus, unabhängig von der Dateigröße. Lesevorgänge verlaufen über einen mehrstufigen Cache: lokale Festplatte auf dem Client, eine verteilte Cache-Ebene für Shared-Node-Deployments und schließlich der Objektspeicher selbst. Die Enterprise Edition ergänzt ein Mirror-Dateisystem, das die Metadatenebene regionen- oder cloudübergreifend repliziert, während ein verteilter Cache statt einer vollständigen Objektspeicherkopie an sekundären Standorten gehalten wird, was regionenübergreifende Bandbreitenkosten reduziert.
Version 1.4 der Community Edition, Mitte 2026 veröffentlicht, erweitert Tiered Storage auf Datei- und Verzeichnisebene. Administratoren können Tier-Bezeichner — ganze Zahlen 1 bis 3 — auf Objektspeicherklassen wie S3 Standard-IA oder Glacier Deep Archive abbilden und diese Tiers einzelnen Pfaden zuweisen. Neu erstellte Dateien erben den Tier des übergeordneten Verzeichnisses. Für Archivklassen, die vor dem Lesen einen Wiederherstellungsschritt erfordern, bietet JuiceFS einen Restore-Befehl; Lesevorgänge gelingen, sobald der Cloud-Anbieter die Objekte zugänglich macht. Das Feature entstand auf Grundlage von Community-Feedback und wird in die Enterprise Edition portiert.
Die Enterprise Edition erreichte 2025 eine validierte Skalierung von 500 Milliarden Dateien in einem einzelnen Volume. CEO Davis Liu hat öffentlich erklärt, das Unternehmen strebe Software an, die in den nächsten 1.500 Jahren relevant bleiben soll — ein ungewöhnlicher Planungshorizont, der eine bewusst konservative Wachstumsstrategie prägt. Ein baldiger Börsengang ist nicht vorgesehen; das Unternehmen setzt derzeit nicht auf Wiederverkauf oder Channelpartner und berechnet für die Enterprise Edition ausschließlich nach Speicherkapazität, ohne Gebühren pro Instanz oder Knoten für die Client-Software.
Reale Deployments verdeutlichen den praktischen Umfang. Xiaomis Cloud-Storage-Team migrierte 2024 seine gesamte Big-Data- und KI-Infrastruktur auf eine einheitliche JuiceFS-Grundlage und löste damit ein Flickwerk aus HDFS-Clustern, Hochleistungs-Parallel-Dateisystemen und direktem Objektspeicherzugriff ab. Das Team baute eine dreischichtige Speicherarchitektur: eine Kapazitätsschicht auf Basis von Multi-Cloud-Objektspeicher für Exabyte-Skalierung und Hunderte von Milliarden Dateien; eine Leistungsschicht auf Basis von Ceph und All-Flash-Knoten für durchsatzintensives KI-Training; sowie eine Cache-Schicht mit NVMe-Laufwerken über RDMA zur Reduzierung wiederholter Lesezugriffe. Die sequenzielle Lese- und Schreibleistung verdoppelte sich in einigen Szenarien nach der Migration; die Gesamtaufgabendauer sank um 10 bis 30 Prozent; Speicherkosten sanken um rund 70 Prozent in China und 90 Prozent in überseeischen Regionen, wo die bisherige Architektur Daten dreifach auf Cloud-Instanzen und EBS-Volumes repliziert hatte.
KI-Modelltraining gilt als einer der wichtigsten Treiber für die JuiceFS-Adoption. Moderne Trainingsabläufe erfordern Datasets im Petabyte-Maßstab, auf die Forscher über dieselbe Python-Datei-E/A zugreifen, die sie schon immer genutzt haben. Frameworks für S3 umzuschreiben ist unpraktisch; ein POSIX-Dateisystem einzuhängen, das intern auf Objektspeicher basiert, hingegen nicht. Xiaomis autonomes Fahren-Team erzielte mehr als 20 Prozent höheren Durchsatz gegenüber dem bisherigen Hochleistungs-Parallel-Dateisystem nach Aktivierung des RDMA-gestützten Caches und reduzierte die Speicherkosten durch Einzelkopiespeicherung statt Replikation um mehr als 60 Prozent. Die Modellverteilung — das Laden trainierter Gewichte auf Inferenzknoten — wurde auf sequenzielle Lesegeschwindigkeiten von bis zu 16 Gigabyte pro Sekunde und Knoten beschleunigt.
Südkoreas führender Suchmaschinenbetreiber, die Video-Plattform Fly.io, das KI-Unternehmen Minimax und die Analyseplattform Jerry (ClickHouse auf JuiceFS) repräsentieren veröffentlichte Community- und Enterprise-Referenzkunden. Das Fly.io-Deployment ist technisch ungewöhnlich: Jeder leichtgewichtige Container erhält ein JuiceFS-Volume, das SQLite als Metadaten-Engine nutzt; ein separates Open-Source-Tool streamt die SQLite-Datei in Objektspeicher, sodass das Volume Containerneustarts ohne angebundenen Blockspeicher übersteht.
Die Wettbewerbspositionierung richtet JuiceFS gegen Lustre, WEKA, Panasas und IBM Spectrum Scale bei Hochleistungs-Workloads sowie gegen Amazons kürzlich eingeführtes S3 Files — eine verwaltete Dateisystemschicht auf S3 — bei Cloud-nativen Deployments. Der Referent wies darauf hin, dass bestehende Objektspeicher-Datasets über den Befehl juicefs import im Nur-Lese-Modus in JuiceFS importiert werden können, wobei Metadaten geladen werden, ohne die zugrunde liegenden Objekte umzuformatieren.
Der Marktzugang für den westlichen Markt befindet sich in einer frühen Phase. Die Boston-Session wurde von dem ersten Developer-Marketing-Mitarbeiter in Nordamerika präsentiert. Zwei anstehende OEM-Gespräche — eines mit einem sri-lankischen Systemintegrator, eines mit Vimeo zur On-Premises-Speicherung — deuten auf einen im Aufbau befindlichen indirekten Vertriebskanal hin. Die Preisgestaltung ist kapazitätsbasiert; der Datentransfer zwischen JuiceFS-Client und Objektspeicher ist direkt und fällt bei Juicedata ohne zusätzliche Gebühr an.
Die grundlegende Wette lautet, dass Objektspeicher zum universellen Datensubstrat geworden ist und eine Dateisystem-Abstraktionsschicht darüber unabhängig von einem einzelnen Cloud-Anbieter den Aufbau und die Pflege lohnt. JuiceFS setzt diese Wette in Open Source unter der Apache-2.0-Lizenz für die Community Edition um, mit einer geschlossenen Enterprise Edition für Unternehmen, die das Mirror-Dateisystem, die Skalierungsgarantien für 500 Milliarden Dateien und kommerziellen Support benötigen.

Dr. Jakob Jung ist Chefredakteur Security Storage und Channel Germany. Er ist seit mehr als 20 Jahren im IT-Journalismus tätig. Zu seinen beruflichen Stationen gehören Computer Reseller News, Heise Resale, Informationweek, Techtarget (Storage und Datacenter) sowie ChannelBiz. Darüber hinaus ist er für zahlreiche IT-Publikationen freiberuflich tätig, darunter Computerwoche, Channelpartner, IT-Business, Storage-Insider und ZDnet. Seine Themenschwerpunkte sind Channel, Storage, Security, Datacenter, ERP und CRM.
Kontakt – Contact via Mail: jakob.jung@security-storage-und-channel-germany.de