Juicedata presents JuiceFS as a POSIX-compatible, object-storage-native distributed file system designed to replace fragmented storage architectures across AI training, big data, and cloud-native environments as shown on IT Press Tour.
When Nvidia CEO Jensen Huang presented partner logos during a keynote in Taiwan earlier this year, a product manager at Juicedata took a screenshot and mentally edited the slide. The company was not on it. “One day we will be there,” the developer advocate told journalists at IT Press Tour #68 in Boston in June 2026. The candour captures something essential about Juicedata: a 35-person, China-headquartered company that is already profitable and competes directly with established high-performance file-system vendors, yet remains largely invisible to Western enterprise buyers.
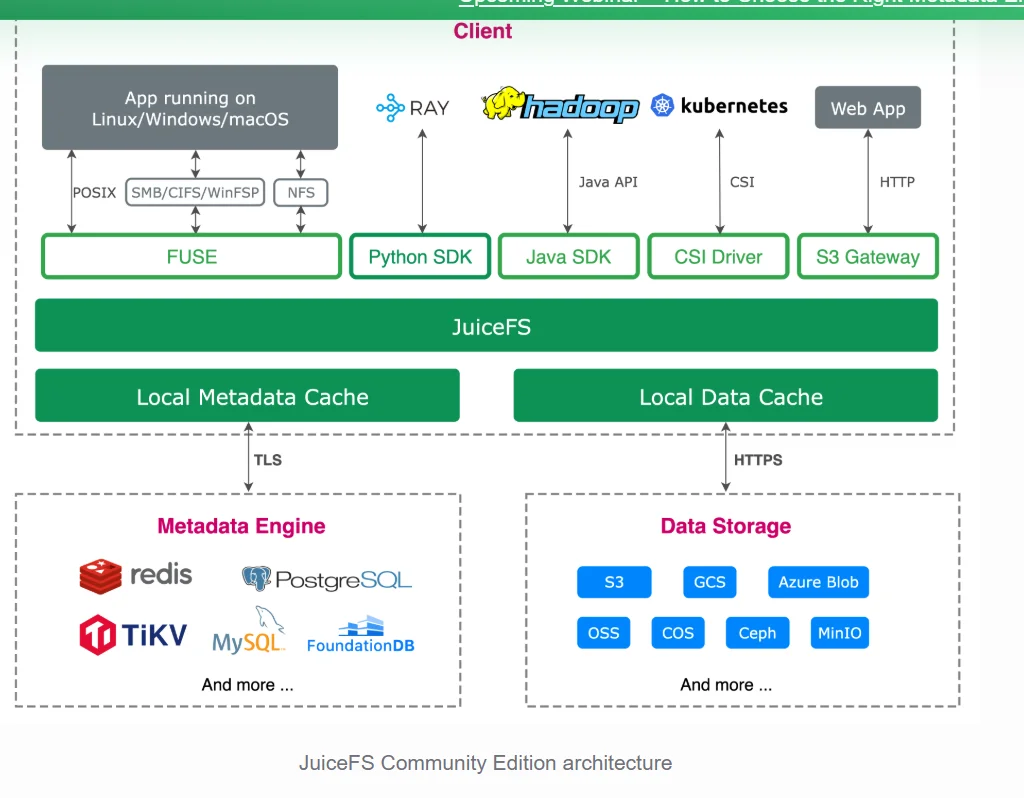
JuiceFS is a distributed file system built on top of object storage services. Its architecture separates data from metadata: actual file content is stored in standard object storage — Amazon S3, Google Cloud Storage, MinIO, Ceph or any S3-compatible backend — while metadata is managed by a pluggable engine such as Redis, PostgreSQL, TiKV, or the company’s proprietary distributed service. The client layer speaks POSIX, HDFS, and S3 protocols simultaneously, which means existing Hadoop pipelines, Python machine-learning frameworks and Kubernetes persistent volumes can all mount the same file system without code changes.
The design choice to rely on object storage is deliberate. Object storage is effectively infinite in capacity, carries eleven nines of durability, supports multi-region replication natively and, at two cents per gigabyte per month on Amazon S3, is substantially cheaper than block or purpose-built file storage. The challenge has always been that object stores expose a flat key-value namespace and immutable objects, not the hierarchical directories and random-write semantics that most applications expect. JuiceFS resolves this by chunking files into fixed-size blocks, keeping only the chunk-to-object mapping in the metadata engine, and presenting a standard POSIX interface to the application.
Because renames and moves are pure metadata operations — no bytes are copied between objects — JuiceFS can execute them with a single write to the metadata engine regardless of file size. Reads proceed through a multi-layer cache: local disk on the client, a distributed cache tier for shared-node deployments, and finally the object store itself. The enterprise edition adds a mirror file system feature that replicates the metadata plane across regions or clouds while keeping a distributed cache rather than a full object-store copy at secondary sites, reducing cross-region bandwidth costs.
Version 1.4 of the community edition, released in mid-2026, extends tiered storage to the file and directory level. Administrators can map tier identifiers — integers 1 through 3 — to object storage classes such as S3 Standard-IA or Glacier Deep Archive, then assign those tiers to individual paths. Newly created files inherit the tier from their parent directory. For archival classes that require a restore step before reading, JuiceFS exposes a restore command; reads succeed once the cloud provider makes the objects accessible. The feature was driven by community requests and is being ported into the enterprise edition.
The enterprise edition reached a validated scale of 500 billion files in a single volume during 2025. Juicedata’s CEO Davis Liu has stated publicly that the company aims for software that will remain relevant for the next 1,500 years — an unusual planning horizon that shapes a deliberately conservative growth strategy. The company does not plan a near-term IPO, does not rely on resellers or channel partners at present, and prices the enterprise edition on storage capacity only, with no per-instance or per-node charges for the client software.
Real-world deployments illustrate the practical scope. Xiaomi’s cloud storage team migrated its entire big-data and AI infrastructure to a unified JuiceFS foundation during 2024, retiring a patchwork of HDFS clusters, high-performance parallel file systems and object-storage direct access. The team built a three-layer storage architecture: a capacity tier backed by multi-cloud object storage targeting exabyte scale and hundreds of billions of files; a performance tier built on Ceph and all-flash nodes for high-throughput AI training; and a cache tier using NVMe drives connected over RDMA to reduce repeated read costs. Sequential read and write performance more than doubled in some scenarios after the migration; overall task duration fell by 10 to 30 percent; storage costs dropped by approximately 70 percent in China and 90 percent in overseas regions where the previous architecture had replicated data three times across cloud instances and EBS volumes.
AI model training represents one of the main drivers of JuiceFS adoption. Modern training runs require petabyte-scale datasets that researchers access through the same Python file I/O they have always used. Rewriting frameworks to speak S3 is impractical; mounting a POSIX file system that happens to be backed by object storage is not. Xiaomi’s autonomous driving team measured throughput more than 20 percent above its previous high-performance parallel file system after enabling the RDMA-backed cache, while reducing storage costs by more than 60 percent through single-copy storage rather than replication. Model distribution — loading trained weights onto inference nodes — was accelerated to sequential read speeds of up to 16 gigabytes per second per node.
South Korea’s leading search engine, the video-hosting platform Fly.io, the AI company Minimax and the analytics platform Jerry (ClickHouse on JuiceFS) represent published community and enterprise reference customers. Fly.io’s deployment is technically unconventional: each lightweight container receives a JuiceFS volume backed by SQLite as the metadata engine; a separate open-source tool streams the SQLite file to object storage, allowing the volume to survive container restarts without attached block storage.
Competitive positioning places JuiceFS against Lustre, WEKA, Panasas and IBM Spectrum Scale for high-performance workloads, and against Amazon’s recently launched S3 Files — a managed file-system layer on S3 — for cloud-native deployments. The presenter noted that existing object-store datasets can be imported into JuiceFS in read-only mode using the juicefs import command, which loads metadata without reformatting the underlying objects; writes to the imported volume use the native JuiceFS chunked format in a separate path.
Go-to-market for the Western market remains early-stage. The Boston session was handled by what the presenter described as Juicedata’s first developer-marketing hire in North America. Two nascent OEM conversations — one with a Sri Lankan system integrator, one with Vimeo exploring on-premises storage — indicate an emerging indirect channel. Pricing is capacity-based; data transfer between the JuiceFS client and the object store is direct and carries no additional Juicedata fee.
The fundamental bet is that object storage has become the universal data substrate and that a file-system abstraction layer on top of it is worth building and maintaining independently of any single cloud provider. JuiceFS makes that bet in open source under the Apache 2.0 licence for the community edition, with a closed enterprise edition for organisations that need the mirror file system, the 500-billion-file scale guarantees, and commercial support.

Dr. Jakob Jung is Editor-in-Chief of Security Storage and Channel Germany. He has been working in IT journalism for more than 20 years. His career includes Computer Reseller News, Heise Resale, Informationweek, Techtarget (storage and data center) and ChannelBiz. He also freelances for numerous IT publications, including Computerwoche, Channelpartner, IT-Business, Storage-Insider and ZDnet. His main topics are channel, storage, security, data center, ERP and CRM.
Contact via Mail: jakob.jung@security-storage-und-channel-germany.de