DeepSeek releases its 1.6-trillion parameter model, leveraging sparse attention and Engram memory to challenge frontier AI economics.
The release of DeepSeek-V4-Pro represents a calculated move toward massive-scale efficiency. By integrating 1.6 trillion parameters within a Mixture-of-Experts (MoE) framework, the model addresses the dual challenges of high-capacity reasoning and computational overhead. This technical leap, underpinned by novel memory architectures and stable training protocols, signals a shift in how frontier models are constructed and deployed.
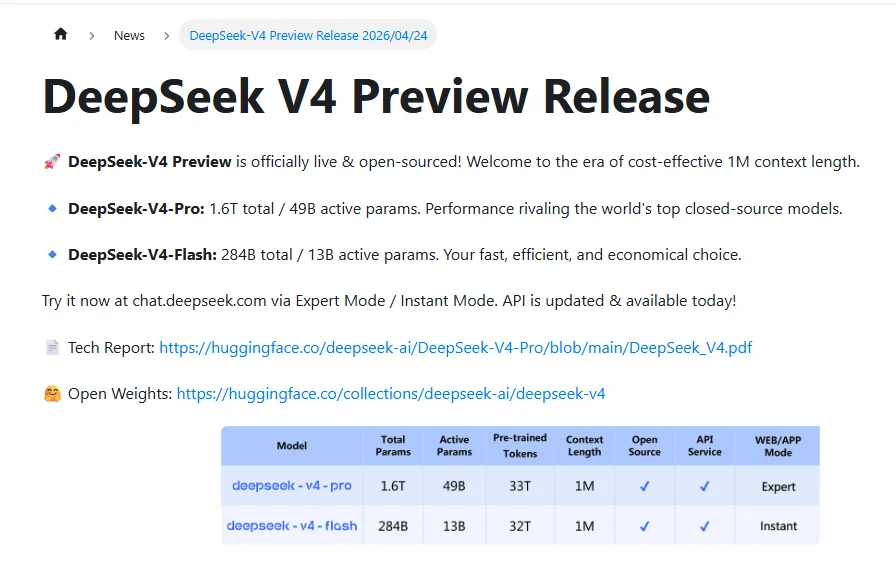
The release of DeepSeek-V4-Pro marks a significant shift in the Mixture-of-Experts (MoE) landscape. With 1.6 trillion total parameters and 49 billion active parameters, the model maintains a high knowledge capacity while optimizing inference costs. Key architectural innovations include Manifold-Constrained Hyper-Connections (mHC) for training stability and Engram Conditional Memory, which decouples static knowledge retrieval from active reasoning. The inclusion of a 1-million-token context window—supported by a hybrid attention system—positions the model as a primary tool for large-scale codebase analysis and complex agentic workflows.
Architecture remains the focal point of the DeepSeek-V4-Pro development. Unlike previous iterations that focused on simple scaling, V4-Pro introduces Manifold-Constrained Hyper-Connections (mHC). This technique stabilizes the training of trillion-parameter systems by constraining gradient flow within defined mathematical manifolds, preventing the instability often seen in massive MoE setups.
The model’s memory management is equally transformative. Through Engram Conditional Memory, DeepSeek separates the retrieval of static information from dynamic reasoning tasks. This allows the system to offload a portion of its sparse parameters to high-bandwidth DRAM, achieving a 97% accuracy in “Needle-in-a-Haystack” tests. This efficiency is critical for the 1-million-token context window, enabling the processing of entire software repositories without the quadratic latency costs typical of standard transformer architectures.
For professional workflows, the 49 billion active parameters ensure that while the model possesses vast knowledge, the energy and financial cost per token remain competitive. Optimized for hardware like the Huawei Ascend 950 and NVIDIA systems, V4-Pro is designed for “agentic” tasks—autonomous coding, multi-step planning, and cross-file refactoring. By balancing the “ceiling” of open-source performance with aggressive price-to-performance ratios, DeepSeek-V4-Pro establishes a new benchmark for accessible, high-tier artificial intelligence.
By integrating 1.6 trillion total parameters within a Mixture-of-Experts (MoE) framework—yet activating only 49 billion per token—the V4-Pro model presents a blueprint for achieving massive capacity while managing computational overhead.
The Two-Model Strategy: Pro and Flash
The V4 series follows a dual-model strategy to cater to different needs, a common industry practice for maximizing market reach:
| DeepSeek-V4-Pro | DeepSeek-V4-Flash | |
|---|---|---|
| Positioning | Flagship, peak capability | Lightweight, speed & cost efficiency |
| Total Parameters | 1.6 Trillion | 284 Billion |
| Activated Parameters | 49 Billion | 13 Billion |
| Pre-training Data | 33 Trillion tokens | 32 Trillion tokens (or 32T+) |
| Architecture | MoE | MoE |
The “activated parameters” are the key to this efficiency. Unlike a dense model, which uses all its parameters for every calculation, an MoE model dynamically routes a token to only a subset of its “expert” sub-networks. This selective activation allows DeepSeek-V4-Pro to possess the knowledge of a massive model at the computational cost of a much smaller one.
Redefining the Economics of Long Context
The headline capability of DeepSeek-V4-Pro is its 1-million-token context window, a near 10x increase from its predecessor’s 128K. More significant than the capacity itself is the efficiency with which it is achieved. The model addresses the quadratic complexity of standard attention, where processing longer sequences becomes prohibitively expensive.
“From now on, 1M context will be the standard for all DeepSeek official services.” — DeepSeek in its release announcement.
DeepSeek achieves this through a novel Hybrid Attention Architecture, combining two new mechanisms: Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). CSA filters out irrelevant information before computation, while HCA aggressively compresses the KV cache, the memory bottleneck for long sequences. This architectural overhaul allows the 1-million-token window to function not as an expensive add-on, but as a foundational feature.
Cost Efficiency in Numbers: FLOPs and KV Cache
The impact of these architectural changes is best understood through two key metrics: FLOPs (floating point operations, a measure of computation) and KV Cache (memory usage). According to DeepSeek’s technical report, in a 1M token context setting:
-
FLOPs per token: V4-Pro requires only 27% of V3.2’s computation.
-
KV Cache: V4-Pro uses only 10% of V3.2’s KV cache.
In other words, while the V3.2’s context window was 128K, the V4-Pro handles a nearly 8x larger context with less computation per token than its predecessor. This shift makes true long-context reasoning practical for the first time at scale.
Key Innovations: Muon, mHC, and Engram Memory
-
Muon Optimizer: The model uses the Muon optimizer instead of the more common AdamW. This choice leads to faster convergence and greater stability during the training of trillion-parameter models.
-
Manifold-Constrained Hyper-Connections (mHC): This technique enhances standard residual connections to stabilize gradient flow across a massive 1.6T-parameter network, a notorious challenge in training very deep MoE models.
-
Engram Conditional Memory: This architecture separates the retrieval of static knowledge from active reasoning. By offloading some parameters to high-bandwidth DRAM, the system can manage its 1M context window without incurring the quadratic latency costs typical of standard transformers. In “Needle-in-a-Haystack” tests for long-range recall, it achieves 97% accuracy.
Performance Benchmarks: Code, Reasoning, and Agentic Work
DeepSeek positions V4-Pro as the strongest open-source model, though it offers a candid self-assessment, stating it trails leading closed-source models by approximately 3 to 6 months. Detailed benchmarks from the company paint a clear picture of its strengths:
-
Top-Tier Performance: In coding benchmarks, V4-Pro is a standout. It achieves a Codeforces rating of 3206, the highest among the four leading models. It also scores 90.2% on the challenging Apex Shortlist benchmark, surpassing both Opus 4.6 and GPT-5.4.
-
Agentic Coding: The Pro version’s agent capabilities are significantly enhanced, particularly for autonomous coding tasks. DeepSeek reports that V4-Pro has become the internal standard for its employees, noting that the “user experience is superior to Sonnet 4.5, and the delivery quality is close to Opus 4.6’s non-thinking mode”.
-
World Knowledge: In world knowledge assessments, V4-Pro significantly outperforms all other open-source models and trails only Google’s closed-source Gemini 3.1-Pro among the top-tier models.
-
Reasoning: The model also shows strong reasoning capabilities. On the SWE Verified coding and reasoning benchmark, V4-Pro matches the 80.6% score of Opus 4.6.
For a more detailed view, here are DeepSeek’s own direct comparisons of key text-based performance metrics between V4-Pro, V4-Flash, and V3.2:
| Category | Benchmark | DeepSeek-V3.2 (671B) | DeepSeek-V4-Flash (284B) | DeepSeek-V4-Pro (1.6T) |
|---|---|---|---|---|
| World Knowledge | MMLU (EM) | 87.8 | 88.7 | 90.1 |
| MMLU-Pro (EM) | 65.5 | 68.3 | 73.5 | |
| Simple-QA verified (EM) | 28.3 | 30.1 | 55.2 | |
| Language & Reasoning | HellaSwag (EM) | 86.4 | 85.7 | 88.0 |
| Code & Math | HumanEval (Pass@1) | 62.8 | 69.5 | 76.8 |
| MATH (EM) | 60.5 | 57.4 | 64.5 | |
| Long Context | LongBench-V2 (EM) | 40.2 | 44.7 | 51.5 |
Optimized for Hardware Autonomy
DeepSeek has optimized the V4 series for specific hardware, signaling a strategic move toward greater hardware independence in the face of ongoing US export restrictions. The model is designed to run on Huawei’s Ascend 950 chips in addition to NVIDIA systems. This collaboration is a significant proof of concept for China’s domestic AI hardware supply chain.
DeepSeek has noted that the throughput for V4-Pro is currently limited by computational supply, but that “prices will drop significantly” in the second half of 2026 “once Huawei’s Ascend 950 super nodes ship at scale”.
API Access, Services, and Pricing
The V4-Pro and V4-Flash models are available immediately via DeepSeek’s API. The API supports both the OpenAI ChatCompletions interface and Anthropic’s API standard for easy integration. For users of the DeepSeek platform, the deepseek-chat and deepseek-reasoner model names will be fully retired on July 24th, 2026, and must be replaced with the new deepseek-v4-pro or deepseek-v4-flash names.
The pricing strategy continues to disrupt the market, with the Flash version in particular offering world-class AI performance at a fraction of the cost. Below is a comparison of the API input and output costs for DeepSeek-V4 models per 1 million tokens, including a special caching discount:
| Model | Context Window | Price per 1M Input Tokens | Price per 1M Output Tokens |
|---|---|---|---|
| DeepSeek-V4-Pro | 1 Million tokens | ~~$2.40~~ $1.74 (cache-hit: $0.14) |
$3.48 |
| DeepSeek-V4-Flash | 1 Million tokens | ~~$0.21~~ $0.14 (cache-hit: $0.03) |
$0.28 |
Table pricing based on DeepSeek’s official API page; pricing subject to change.

Dr. Jakob Jung is Editor-in-Chief of Security Storage and Channel Germany. He has been working in IT journalism for more than 20 years. His career includes Computer Reseller News, Heise Resale, Informationweek, Techtarget (storage and data center) and ChannelBiz. He also freelances for numerous IT publications, including Computerwoche, Channelpartner, IT-Business, Storage-Insider and ZDnet. His main topics are channel, storage, security, data center, ERP and CRM.
Contact via Mail: jakob.jung@security-storage-und-channel-germany.de